publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
 When Are Teacher Tokens Reliable? Position-Weighted On-Policy Self-Distillation for ReasoningXiaogeng Liu, Xinyan Wang, Yingzi Ma, Yechao Zhang, and Chaowei XiaoarXiv preprint arXiv:2605.21606, 2026
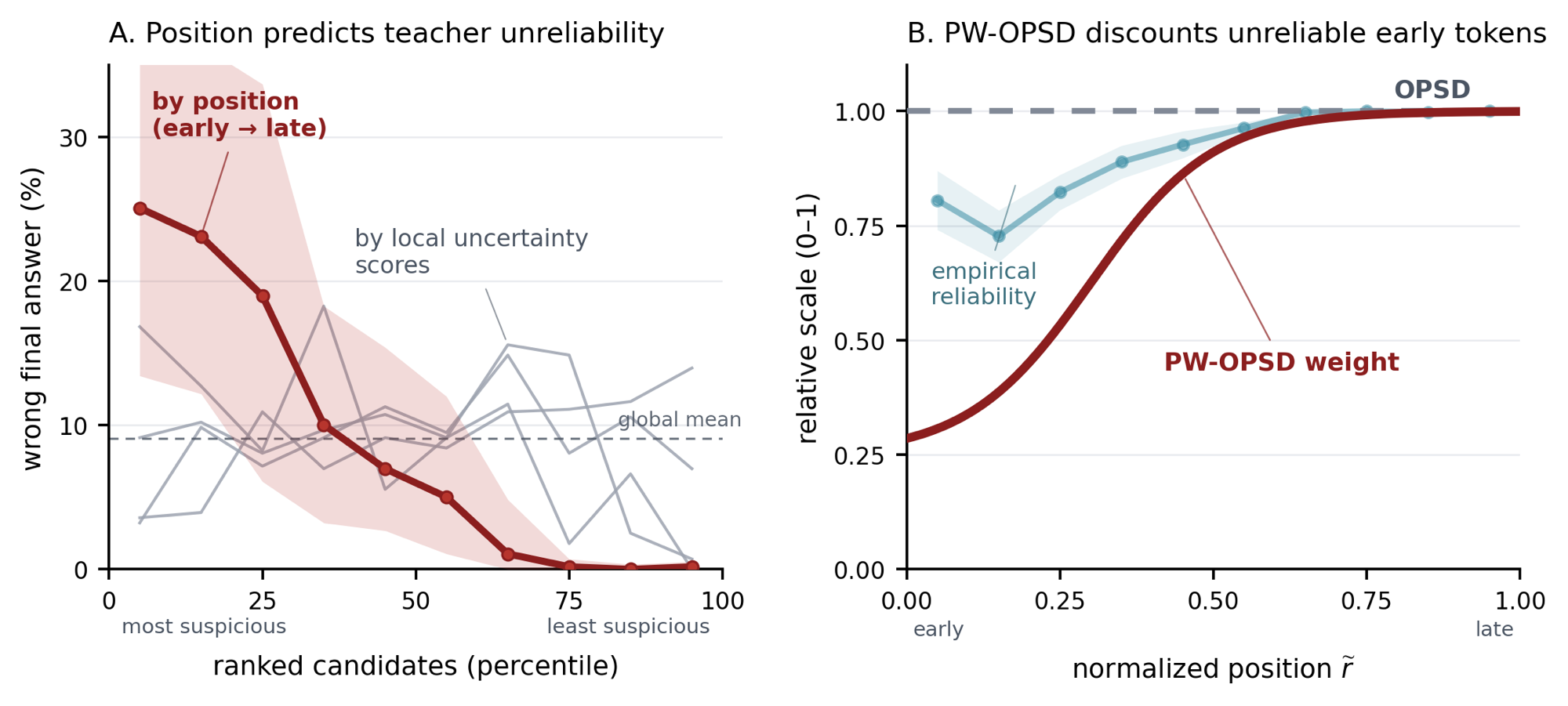
When Are Teacher Tokens Reliable? Position-Weighted On-Policy Self-Distillation for ReasoningXiaogeng Liu, Xinyan Wang, Yingzi Ma, Yechao Zhang, and Chaowei XiaoarXiv preprint arXiv:2605.21606, 2026On-policy self-distillation (OPSD) trains a student on its own rollouts using a privileged teacher, but its standard objective weights all generated tokens equally, implicitly treating the privileged teacher target as equally reliable at every student-visited prefix. Existing entropy-based OPD methods relax this uniformity by modulating token-level supervision with teacher entropy, but high teacher entropy in reasoning has an ambiguous reliability meaning: it can reflect either non-viable uncertainty or benign solution diversity. To identify this phenomenon, we introduce a branch-viability diagnostic. Specifically, we record next-token alternatives from the privileged-answer teacher prompt, force each alternative after the student prompt plus its on-policy spine prefix, and test whether the resulting student-template continuation recovers the correct answer. On Qwen3-4B, we find that an oriented within-sequence position score is the strongest tested predictor of teacher-token reliability, reaching an area-under-ROC-curve (AUROC) of 0.83 with a 95% cluster-bootstrap interval of [0.66, 0.95]; local uncertainty scores are at most 0.57. Motivated by this trajectory-level structure, we propose Position-Weighted On-Policy Self-Distillation (PW-OPSD), which applies an increasing position weight while keeping the same student rollout, privileged teacher pass, and clipped forward-KL target as OPSD. In our comprehensive evaluations with different random seeds, the diagnostic-derived PW-OPSD improves AIME 2024 and AIME 2025 Avg@12 by +1.0 and +1.1 points, and a generalization evaluation on two larger-scale models from different families, DeepSeek-R1-Distill-Llama-8B and Olmo-3-7B-Think, also demonstrates consistent aggregate Avg@12 improvements. These results show that teacher-token reliability in reasoning distillation is trajectory-structured and can be utilized without additional teacher computation. The code is available at https://github.com/SaFo-Lab/PW-OPSD.
@article{liu2026pwopsd, title = {When Are Teacher Tokens Reliable? Position-Weighted On-Policy Self-Distillation for Reasoning}, author = {Liu, Xiaogeng and Wang, Xinyan and Ma, Yingzi and Zhang, Yechao and Xiao, Chaowei}, journal = {arXiv preprint arXiv:2605.21606}, year = {2026}, eprint = {2605.21606}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, } -
 ROM: Real-time Overthinking Mitigation via Streaming Detection and InterventionXinyan Wang, Xiaogeng Liu, and Chaowei XiaoarXiv preprint arXiv:2603.22016, 2026
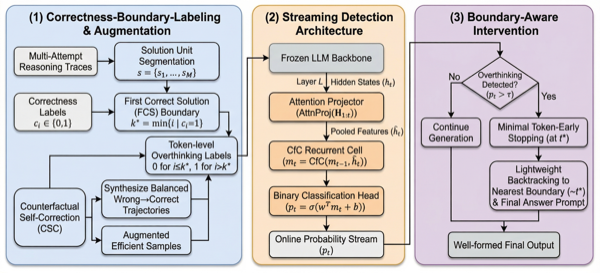
ROM: Real-time Overthinking Mitigation via Streaming Detection and InterventionXinyan Wang, Xiaogeng Liu, and Chaowei XiaoarXiv preprint arXiv:2603.22016, 2026Large Reasoning Models (LRMs) often reach a correct solution before their long Chain-of-Thought trace ends, yet continue with redundant verification, repeated attempts, or unnecessary exploration that wastes computation and can even overturn the correct answer. We frame this behavior as a latent productive-to-redundant transition and show that it is directly reflected in hidden states: around first-correct-solution (FCS) boundaries, late-layer representations separate efficient from overthinking tokens, while boundary-permutation and position-control baselines collapse. Based on this signal, we propose ROM, a model-agnostic streaming intervention framework that monitors frozen LRMs with a lightweight hidden-state detector and intervenes at well-formed reasoning boundaries. Counterfactual Self-Correction (CSC) augments supervision with balanced wrong-to-correct trajectories, preserving useful pre-FCS correction while labeling only post-FCS continuation as redundant. Across MATH500, GSM8K, AIME25, and MMLU-Pro, ROM improves the overall tradeoff on both Qwen3-8B and DeepSeek-R1-Distill-Qwen-32B (DS-32B): on Qwen3-8B, it raises accuracy from 74.47% to 74.78% and reduces response length from 4262 to 3107 tokens; on DS-32B, it raises accuracy from 68.60% to 68.72% and reduces response length from 3062 to 2319 tokens. The same FCS-derived supervision transfers across scale and training origin, suggesting a shared long-CoT boundary rather than a backbone-specific artifact. ROM is compatible with L1, removing another 20.9–21.6% tokens at zero accuracy loss. ROM also generalizes to open-ended MMLU-Pro (+1.56 pp, 35.4% shorter) and reduces wall-clock latency by 46.5%.
@article{wang2026rom, title = {ROM: Real-time Overthinking Mitigation via Streaming Detection and Intervention}, author = {Wang, Xinyan and Liu, Xiaogeng and Xiao, Chaowei}, journal = {arXiv preprint arXiv:2603.22016}, year = {2026}, eprint = {2603.22016}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, } -
 ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning ModelsXiaogeng Liu, Xinyan Wang, Yechao Zhang, Sanjay Kariyappa, Chong Xiang, Muhao Chen, G. Edward Suh, and Chaowei XiaoIn Proceedings of the ACM Conference on Computer and Communications Security (CCS), 2026
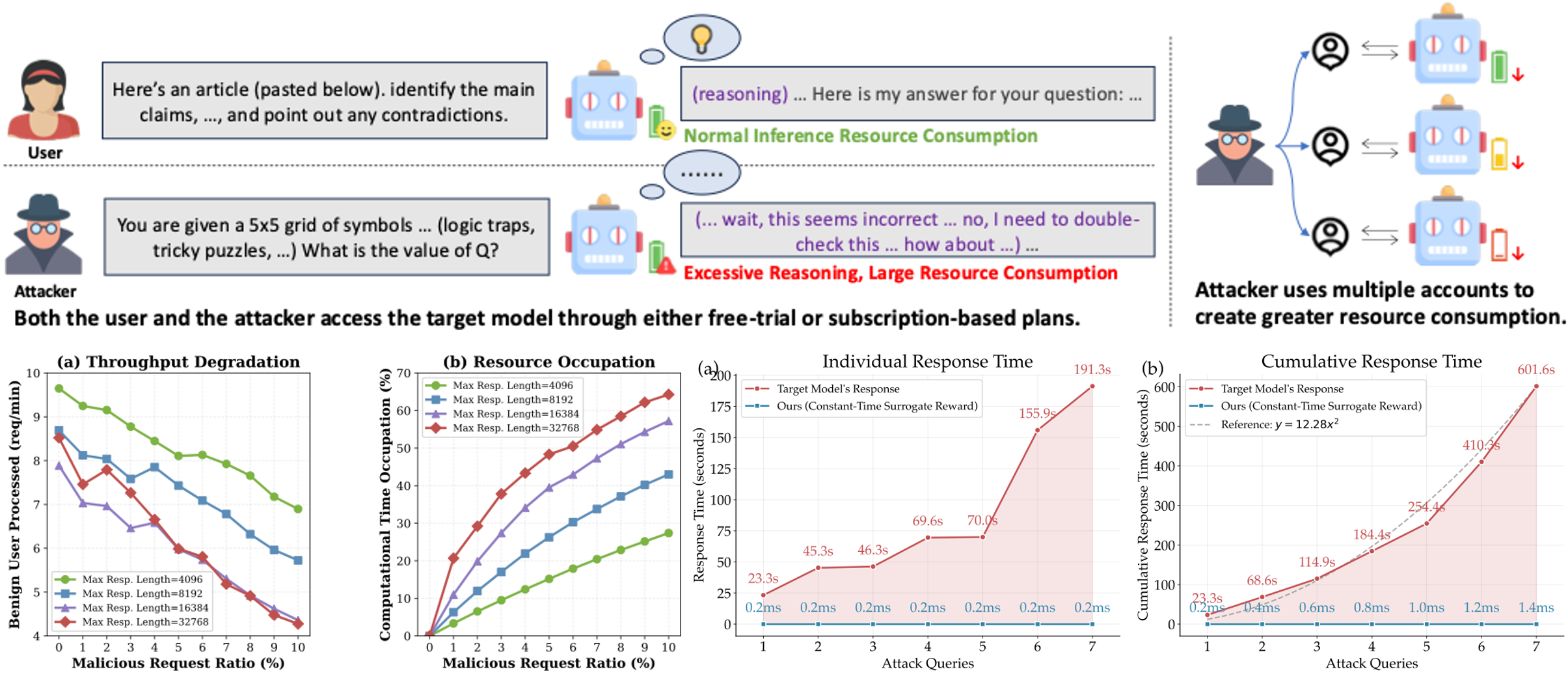
ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning ModelsXiaogeng Liu, Xinyan Wang, Yechao Zhang, Sanjay Kariyappa, Chong Xiang, Muhao Chen, G. Edward Suh, and Chaowei XiaoIn Proceedings of the ACM Conference on Computer and Communications Security (CCS), 2026Large reasoning models (LRMs) extend large language models with explicit multi-step reasoning traces, but this capability introduces a new class of prompt-induced inference-time denial-of-service (PI-DoS) attacks that exploit the high computational cost of reasoning. We first formalize inference cost for LRMs and define PI-DoS, then prove that any practical PI-DoS attack should satisfy three properties: (1) a high amplification ratio, where each query induces a disproportionately long reasoning trace relative to its own length; (ii) stealthiness, in which prompts and responses remain on the natural language manifold and evade distribution shift detectors; and (iii) optimizability, in which the attack supports efficient optimization without being slowed by its own success. Under this framework, we present ReasoningBomb, a reinforcement-learning-based PI-DoS framework that is guided by a constant-time surrogate reward and trains a large reasoning-model attacker to generate short natural prompts that drive victim LRMs into pathologically long and often effectively non-terminating reasoning. Across seven open-source models (including LLMs and LRMs) and three commercial LRMs, ReasoningBomb induces 18,759 completion tokens on average and 19,263 reasoning tokens on average across reasoning models. It outperforms the runner-up baseline by 35% in completion tokens and 38% in reasoning tokens, while inducing 6-7x more tokens than benign queries and achieving 286.7x input-to-output amplification ratio averaged across all samples. Additionally, our method achieves 99.8% bypass rate on input-based detection, 98.7% on output-based detection, and 98.4% against strict dual-stage joint detection.
@inproceedings{liu2026reasoningbomb, title = {ReasoningBomb: A Stealthy Denial-of-Service Attack by Inducing Pathologically Long Reasoning in Large Reasoning Models}, author = {Liu, Xiaogeng and Wang, Xinyan and Zhang, Yechao and Kariyappa, Sanjay and Xiang, Chong and Chen, Muhao and Suh, G. Edward and Xiao, Chaowei}, booktitle = {Proceedings of the ACM Conference on Computer and Communications Security (CCS)}, year = {2026}, eprint = {2602.00154}, archiveprefix = {arXiv}, primaryclass = {cs.CR}, }



2023
-
 MLE with datasets from populations having shared parametersJun Shao, and Xinyan WangStatistical Theory and Related Fields, 2023
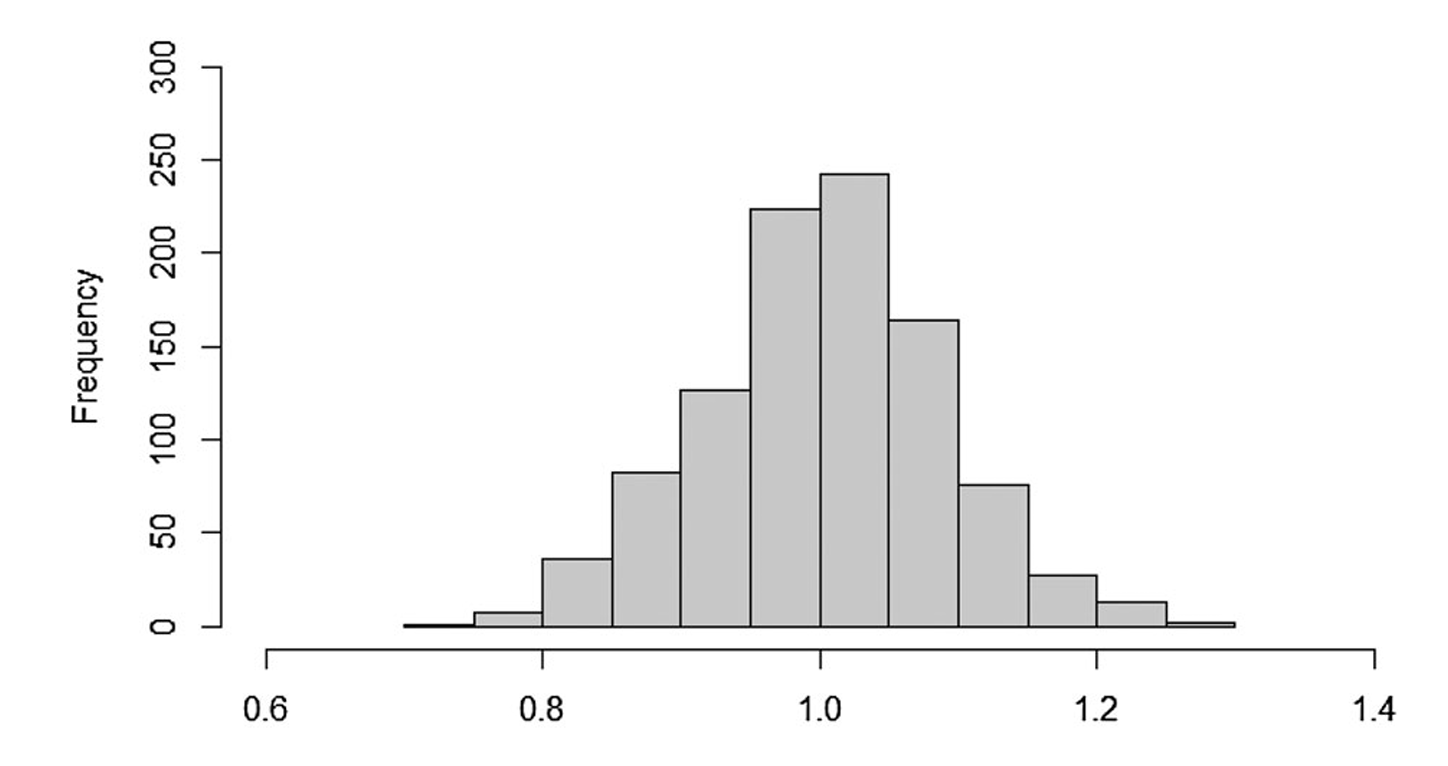
MLE with datasets from populations having shared parametersJun Shao, and Xinyan WangStatistical Theory and Related Fields, 2023We consider maximum likelihood estimation with two or more datasets sampled from different populations with shared parameters. Although more datasets with shared parameters can increase statistical accuracy, this paper shows how to handle heterogeneity among different populations for correctness of estimation and inference. Asymptotic distributions of maximum likelihood estimators are derived under either regular cases where regularity conditions are satisfied or some non-regular situations. A bootstrap variance estimator for assessing performance of estimators and/or making large sample inference is also introduced and evaluated in a simulation study.
@article{shao2023mle, title = {MLE with datasets from populations having shared parameters}, author = {Shao, Jun and Wang, Xinyan}, journal = {Statistical Theory and Related Fields}, volume = {7}, number = {3}, pages = {213--222}, year = {2023}, doi = {10.1080/24754269.2023.2180185}, }
