Motivation: The Productive→Redundant Boundary Is a Decodable Latent Event
We align MATH500 traces at each overthinking boundary, take the last 20 efficient and first 20 overthinking tokens, and probe Qwen3-8B's late-layer hidden states with logistic regression. The two phases are linearly separable at 85.9% accuracy / AUROC 0.928 despite often discussing the same content; probe scores rise sharply at the true boundary but stay flat under permuted alignment; and the signal is not a position shortcut (position-only classifier reaches only 50.3%, and position-residualized hidden states still separate at 86.4%).
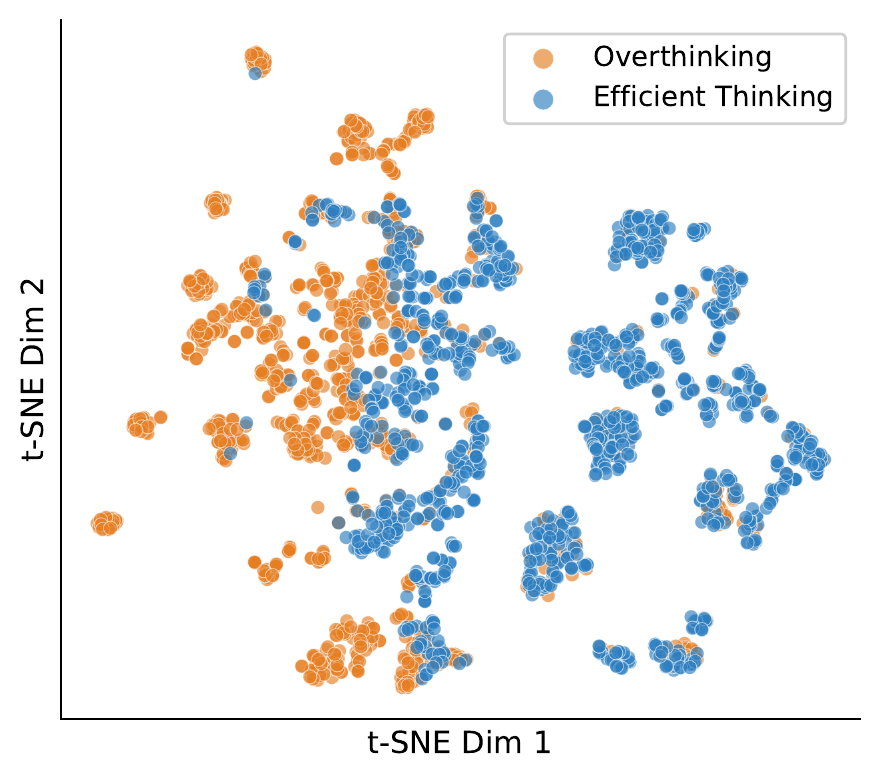
(a) t-SNE of late-layer hidden states separates efficient (pre-FCS) from overthinking (post-FCS) tokens.
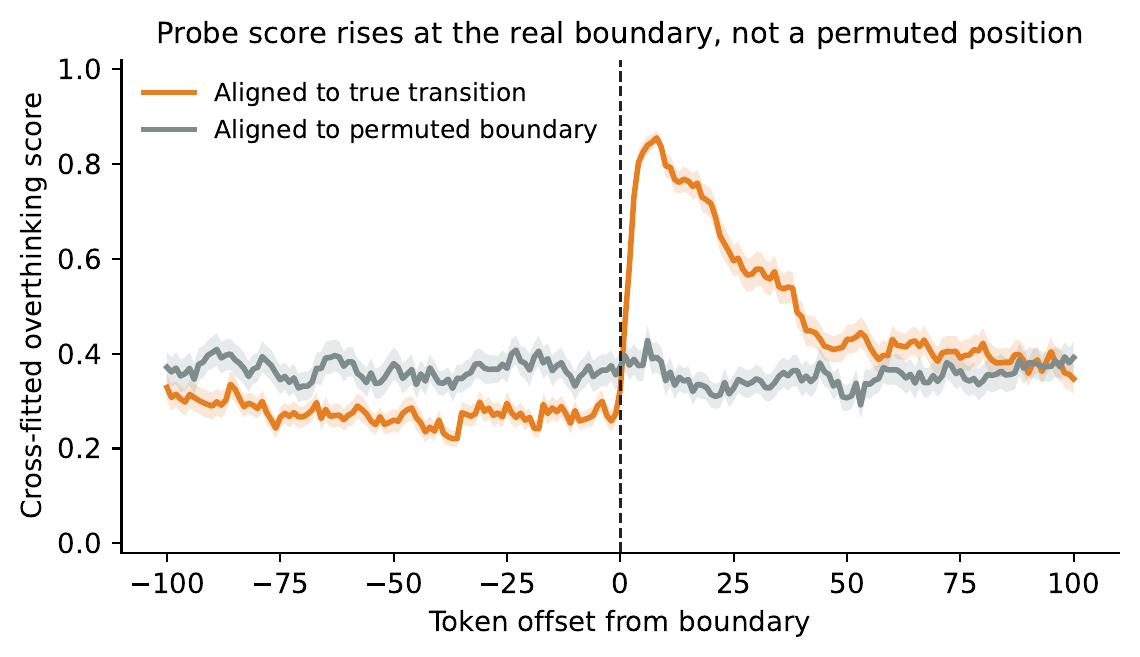
(b) Boundary-aligned probe scores rise sharply at the true FCS; permuted alignment stays flat.
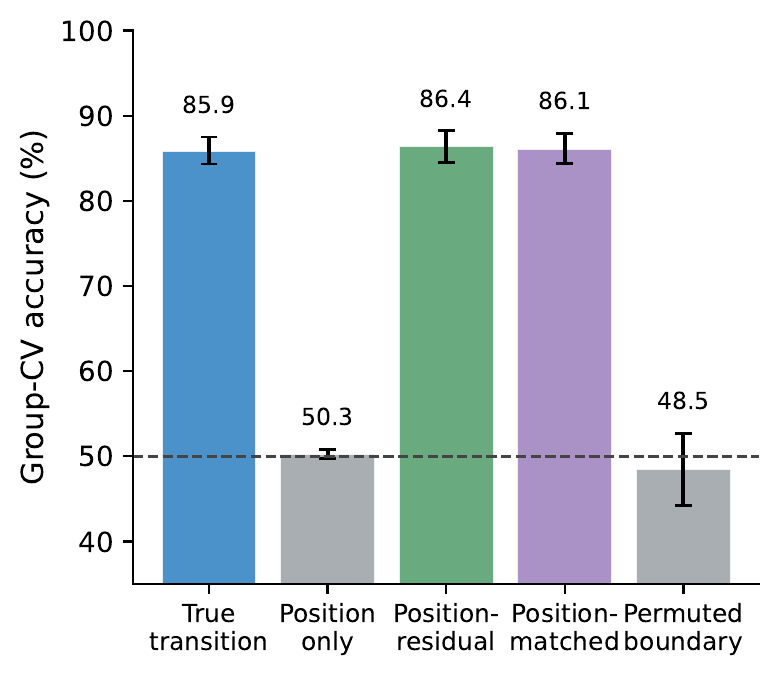
(c) Position-only and permuted-boundary controls collapse to ~50%, ruling out a position shortcut.